使用 Spark 进行数据分析
Spark简介
Apache Spark是个分布式计算框架,其提供了一大批高级API基于批处理或流式处理对大规模数据做ETL、机器学习和图处理等。可以用来开发Spark程序的编程语言有Scala、Python、Java、R和SQL。也可以将其理解成一个具备批处理和流处理能力的分布式数据处理引擎,支持SQL查询、图处理和机器学习等。Spark平台的组件间关系如下图所示:
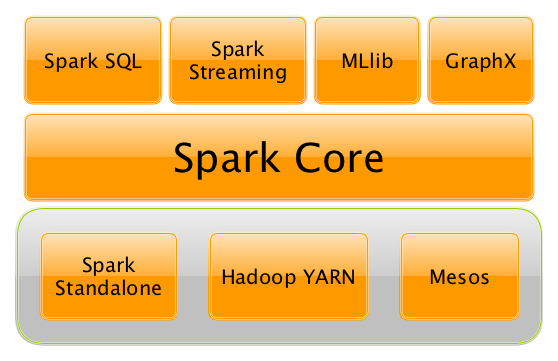
Spark Core是整个Spark平台的核心部分,实现了重要的基础功能,例如输入输出、任务分发和调度、错误恢复等。Spark Core定义了一个特殊的数据结构RDD,并提供了一系列操作RDD的编程API。
Spark SQL是基于Spark API开发的能进行关系型数据处理的组件。该组件赋予Spark开发者对关系型数据处理的能力,也能让SQL用户能进行基于Spark的复杂分析。与Spark Core相比,Spark SQL是个从关系型视角对(半)结构化数据进行处理的框架,我们可以用SQL及SQL风格API来描述业务逻辑。
Spark Architecture
Spark程序可以看作是一组互相独立地跑在集群上的进程,这组进程接受driver进程(main所处的进程)中的SparkContext对象协调的。其简单结构如下图所示:
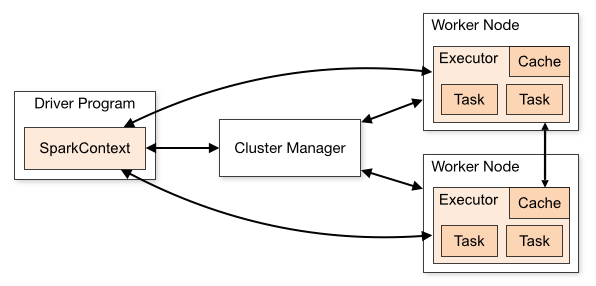
Cluster Manger负责为应用分配集群的资源,SparkContext适配了多种类型的集群(如Spark Standalone、Apache Mesos、Hadoop YARN、Kubernetes,我们实际情况是YARN)。Spark程序运行时,SparkContext首先去找Cluster Manager请求资源(executor,可以执行计算及存储应用数据的进程),然后SparkContext将程序代码分发到各个executor,最后SparkContext把task发送到各个executor去执行。
需要指出以下事项:
- 每个Spark程序获得的是属于自己的executors,这些executors在整个程序运行过程中保持运行,以多线程方式处理任务。这个特点使多个Spark程序在调度侧(每个driver只调度自己的task)和执行侧(不同程序的task跑在不同的JVM里)都是互相隔离的。当然了,如果不把数据持久化到外部,那么不同的Spark程序也就无法共享数据。
- Spark对于集群管理器并不关心,只关心自己要来的executor。
- 程序整个生命周期内,driver必须一直监听着executor发起的连接,这意味这driver和executors是必须网络通畅的。
RDD
RDD(即弹性分布式数据集)是Spark Core中的核心概念之一,是Spark最重要的数据抽象,所有数据处理都是基于对RDD的处理来实现。。从名字上体现出了其一些特点
- 弹性:这里的意思侧重“可恢复”,而不是“可伸缩”。RDD能从各种意外(比如节点挂掉、executor被误杀等)导致的数据丢失或损坏中进行重新计算,是支持错误恢复的
- 分布式:数据分布在集群的各个节点中
- 数据集:数据的集合,数据可以是简单的数值,也可以是更复杂的类型,例如Tuple、List、Map等数据结构,甚至可以是自行定义的类对象
除此之外,RDD有一些其他特点,这里列出几个
- 内存优先:Spark程序运行时,RDD中的数据会尽可能多且尽可能久地保存在内存中
- 不可变/只读:RDD一旦创建就不再可变,只能通过变换生成一个新的RDD
- 延迟计算:在一个action触发了任务实际运行之前,RDD中的数据尚不可及
- 可缓存:可以将RDD中全部数据持久化到某个存储,例如内存(默认及绝大多数情况)或者硬盘(由于硬盘存取速度问题,一般很少这么做)
- 并行化:对RDD数据的处理是并行的
- 类型化:RDD中的数据是有类型的,例如
Long类型数据放在RDD[Long]中,Student对象放在RDD[Student]中
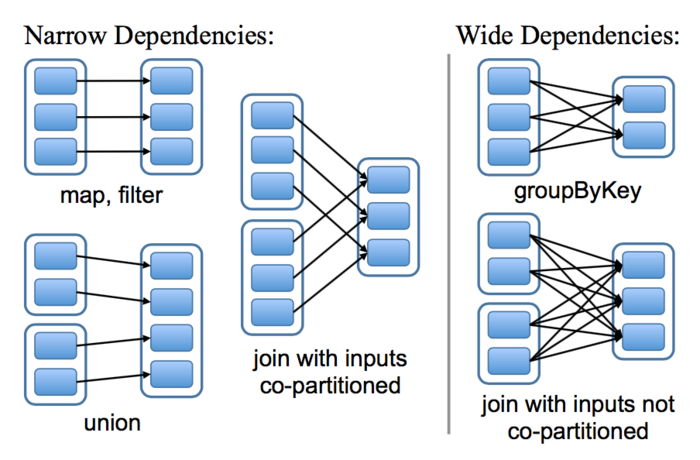
RDD支持两种类型的操作:transformation(转换)和action(动作)。从现有RDD生成新RDD的操作称为transformation,从RDD上运行执行计算然后求得一个值的操作称为action。transformation是延迟计算的。当对一个RDD执行了transformation之后,便构造出了一个“RDD血缘图”,记录了对RDD的变换操作和依赖信息。我们需要对依赖情况做到心里有数,宽窄依赖如下所示:
Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
Dataset[T]&DataFrame
对于Spark SQL而言,Dataset[T]是其核心类之一,所有的操作都是对Dataset的处理(提交的SQL也会首先被解析成操作Dataset)。在内部,所有对Dataset的操作最终转换成RDD的操作。
Dataset是个分布式的数据集合。它是Spark1.6新增的接口,综合了RDD的优势(强类型,强大的λ函数能力)和Spark SQL的优化执行引擎优势。DataFrame是个数据已进行字段命名的Dataset。在Spark SQL中DataFrame=Dataset[Row]
对Dataset的操作也可以分transformation和action两类。其中变换操作(transformation),分为“typed”和“untyped”两类。所谓“typed”,指的是编译时已知要处理的数据的类型(例如操作Dataset[Student]);相对应的,“untyped”指的是编译时不知道要处理的数据的类型(操作DataFrame)。
用Spark处理数据
对于有一些经验的同事,可以考虑深入研究Spark Core部分的算子,对比其使用场景;对于入门且马上要进行数据分析的同事,可以考虑直接使用Spark SQL,只需要一小部分的编程即可,数据分析可以直接以SQL实现。
另一方面,由于Spark Core与Spark SQL可以组合使用(基于Dataset/DataFrame/RDD的互相转换),有经验的同事可以尝试各种操作,入门的话还是建议一步步来。
获取SparkContext&SparkSession对象
SparkContext是Spark服务的入口点,堪比Spark程序的心脏;SparkSession是Spark SQL的入口点。
构造/获取SparkContext对象的方式有很多,例如下面通过SparkConf来构造,但这种方式我用得不多了
1
2
3
|
import org.apache.spark.{SparkConf, SparkContext}
val conf = new SparkConf().setMaster("local[*]").setAppName("LocalSparkApp")
val sc = SparkContext.getOrCreate(conf)
|
开发应用程序时,一般以如下方式获取两者的对象。
1
2
3
4
5
6
7
|
import org.apache.spark.sql.SparkSession
// local spark application
val spark = SparkSession.builder().appName("LocalSparkApp").master("local[*]").getOrCreate()
// spark application
val spark = SparkSession.builder().appName("SparkApp").master("yarn").getOrCreate()
val sc = spark.sparkContext
|
建议:将SparkSession对象命名为spark、将SparkContext对象命名为sc,使之与Spark-Shell环境保持一致。这样核心逻辑代码可以直接拿到Spark-Shell中使用。
Spark-Shell会直接初始化这两者给我们使用(控制台输出的6-7行)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
PS C:\Software\Spark\spark-2.4.5-bin-hadoop2.7\bin> ./spark-shell
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://DESKTOP-9LN67TS.mshome.net:4040
Spark context available as 'sc' (master = local[*], app id = local-1581394859054).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.5
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_241)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
|
Spark Core
Spark Core程序始于SparkContext对象sc。RDD是Spark Core的核心类之一,所有数据处理都是基于对RDD的处理来实现。对其操作分为两类:transformation(转换)和action(动作)。transformation是生成新RDD的操作,例如map filter reduceByKey等,action是得出一个非RDD值的操作,比如count collect take saveAsTextFile等。
parallelize方法是从序列创建一个RDD,生产中一般不用,仅作学习和测试使用。
1
2
|
val rawStr = "Hello World!\naaa bbb ccc ddd\naaa aaa\nbbb\nccc\n"
val lineRdd = sc.parallelize(rawStr.lines.toSeq)
|
textFile方法是读取文本文件创建RDD,RDD中每个元素都是文件中的一行
1
|
val fileRdd = sc.textFile("/path-to-file/")
|
此处简单介绍下常见的算子,我们目前工作中常用的算子有map filter distinct reduceByKey join
map算子:将RDD中的每个元素转换成另一种状态,目标状态不设限
1
2
3
4
5
6
7
|
/*
* lineRdd -> ["Hello World!", "aaa bbb ccc ddd", "aaa aaa", ...]
*
* lowerRdd -> ["hello world!", "aaa bbb ccc ddd", "aaa aaa", ...]
*/
// val lowerRdd = lineRdd.map(line => line.toLowerCase())
val lowerRdd = lineRdd.map(_.toLowerCase)
|
flatMap算子:将RDD中的每个元素转换成一个可枚举的序列,然后将这些序列“压平”(也可以理解成连接起来)
1
2
3
4
5
6
|
/*
* lineRdd -> ["Hello World!", "aaa bbb ccc ddd", "aaa aaa", ...]
*
* wordRdd -> ["Hello", "World!", "aaa", "bbb", ...]
*/
val wordRdd = lineRdd.flatMap(_.split(" "))
|
filter算子:检查每个元素,过滤掉不符合条件的元素
1
2
3
4
5
6
|
/*
* wordRdd -> ["Hello", "World!", "aaa", "bbb", ...]
*
* pureWordRdd -> ["aaa", "bbb", "ccc", "ddd", "aaa", ...]
*/
val pureWordRdd = wordRdd.filter(_.toCharArray.toSet.size == 1)
|
distinct算子:把数据集中的数据去重
1
2
3
4
5
6
|
/*
* pureWordRdd -> ["aaa", "bbb", "ccc", "ddd", "aaa", ...]
*
* distinctRdd -> ["aaa", "bbb", "ccc", "ddd"]
*/
val distinctRdd = pureWordRdd.distinct()
|
count算子:统计RDD中数据的条数
take算子:从RDD中取指定数量的数据放到数组中
1
|
distinctRdd.take(5).foreach(println)
|
collect算子:将RDD中的所有数据收集到数组中(实际不太常用,除非能保证RDD中的数组足够少,能放到一个数组中去)
1
|
distinctRdd.collect.foreach(println)
|
groupBy算子:将RDD中的数据分组
1
2
3
4
5
6
|
/*
* pureWordRdd -> ["aaa", "bbb", "ccc", "ddd", "aaa", ...]
*
* groupedRdd -> ['a'->["aaa", "aaa",...], 'b'->["bbb",...], 'c'->["ccc"], ...]
*/
val groupedRdd = pureWordRdd.groupBy(_.charAt(0))
|
归纳类算子:reduce fold aggregate。这组算子的目标是将RDD归纳成一个值。下面演示其各自用法(功能目标一致,求RDD中字符串长度之和)
1
2
3
4
5
6
|
// def reduce(f: (T, T) => T): T
pureWordRdd.map(_.length).reduce(_ + _)
// def fold(zeroValue: T)(op: (T, T) => T): T
pureWordRdd.map(_.length).fold(0)(_ + _)
// def aggregate[U](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U
pureWordRdd.aggregate(0)((i, s) => i + s.length, _ + _)
|
交并差算子:intersection union subtract。同数学上交集、并集、差集的概念
1
2
3
4
5
6
|
val rdd1 = sc.parallelize(Seq("A", "B", "C")) // [A, B, C]
val rdd2 = sc.parallelize(Seq("B", "C", "D")) // [B, C, D]
rdd1.intersection(rdd2) // rdd1 ∩ rdd2 = [B, C]
rdd1 ++ rdd2 // rdd1 ∪ rdd2 = [A, B, C, B, C, D]
rdd1.union(rdd2) // rdd1 ∪ rdd2 = [A, B, C, B, C, D]
rdd1.subtract(rdd2) // rdd1 - rdd2 = [A]
|
以上算子是操作RDD[T]时常用的,当T是个二元组时,此时RDD[(K, V)]将会被隐式转换成PairRDDFunctions[K, V]对象,此时可以使用一些特殊算子,例如以下介绍的join系算子和xxxByKey系算子
归纳类算子:reduceByKey foldByKey aggregateByKey。下面演示其用法(统计各个Key的个数)
1
2
3
4
5
6
7
8
|
val rdd = sc.parallelize(Seq(("A", "AAA"), ("A", "aaa"), ("B", "bbb")))
// def reduceByKey(func: (V, V) => V): RDD[(K, V)]
rdd.map(t => (t._1, 1)).reduceByKey(_ + _)
// def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]
rdd.map(t => (t._1, 1)).foldByKey(0)(_ + _)
// def aggregateByKey[U](zeroValue: U)(seqOp: (U, V) => U, combOp: (U, U) => U): RDD[(K, U)]
rdd.aggregateByKey(0)((i, _) => i + 1, _ + _)
|
groupByKey算子:该算子不再需要参数,行为与上述groupBy算子行为一致
关联类算子:join leftOuterJoin rightOuterJoin fullOuterJoin,主要区别在于对于关联失败数据的处理方式
1
2
3
4
5
6
7
|
val rdd1 = sc.parallelize(Seq(("A", "aaa"), ("B", "bbb"), ("C", "ccc")))
val rdd2 = sc.parallelize(Seq(("B", "BBB"), ("C", "CCC"), ("D", "DDD")))
rdd1.join(rdd2) // [("B", ("bbb", "BBB")), ("C", ("ccc", "CCC"))]
rdd1.leftOuterJoin(rdd2) // [("A", ("aaa", None)), ("B", ("bbb" ,Some("BBB"))), ("C", ("ccc",Some("CCC")))]
rdd1.rightOuterJoin(rdd2) // [("B", (Some("bbb"), "BBB")), ("C", (Some("ccc"), "CCC")), ("D", (None, "DDD"))]
rdd1.fullOuterJoin(rdd2) // [("A", (Some("aaa"), None)), ("B", (Some("bbb"), Some("BBB"))), ("C", (Some(ccc), Some("CCC"))), ("D", (None, Some("DDD")))]
|
以上算子便是离线数据分析常用的算子,对于数据进行的分析都是基于这些算子的组合使用,常用才能熟悉。关于以上列出算子的官方文档,请参考ScalaDoc:RDD,PairRDDFunctions
对于结果数据保存,我们常用的是saveAsTextFile方法,在调用此方法之前,需要保证数据已经是\t分隔字段的单行字符串形式,一般需要用map算子转换一下数据的形式,如下所示:
1
|
rdd.map(_.mkString("\t")).saveAsTextFile("/path-to-result/")
|
Spark SQL
此处介绍Spark SQL主要为了降低数据处理的门槛,基于我们已经很熟悉的SQL语言,马上就能进行基本的数据处理工作。因此侧重以SQL方式进行数据处理,对DatasetAPI细节介绍较少,若要以编程方式使用,可参考其文档ScalaDoc - Dataset
同样的逻辑,使用DatasetAPI和SQL表达在性能上没有任何差别。
首先给出一段简单代码,用以揭示使用Spark SQL进行数据分析的一般流程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
// --------------- preparing ---------------
// construct schema
val schema = new StructType()
.add("id", DataTypes.LongType, nullable = true)
.add("name", DataTypes.StringType, nullable = true)
.add("age", DataTypes.IntegerType, nullable = true)
.add("score", DataTypes.DoubleType, nullable = true)
// load file, create dataframe
val df = spark.read
.schema(schema)
.option("header", false) // default is false
.option("inferSchema", false) // default is false
.option("sep", "\t")
.csv("/path-to-bcp-file/")
// register as a temp view/table
df.createOrReplaceTempView("tableName")
// --------------- processing ---------------
// execute sql statement
val result = spark.sql("select * from tableName where name is not null and age > 18 and score > 60")
// --------------- saving ---------------
result.write.option("sep", "\t").csv("/path-to-result-dir/")
// --------------- exit ---------------
spark.close()
|
我们主要对数据准备、处理、保存阶段进行详细的讨论。
Preparing
数据准备阶段的工作是告知Spark SQL:我们的数据是什么结构,怎么样能拿到。解答这两个问题的办法有很多,我们视情况选择自己用得顺手的即可。此处给出两类办法以供参考。
- 定义业务数据类型
1
2
3
4
5
6
7
8
9
10
11
12
|
// define class
case class Student(id: String, name: String, age: Int, score: Double)
// read file
val ds = sc.textFile("/path-to-file/") // type: RDD[String] sample: "001,tom,18,60.0"
.map(_.split(",")) // type: RDD[Array] sample: ["001","tom","18","60.0"]
.map(arr => (arr(0), arr(1), arr(2).toInt, arr(3).toDouble)) // type: RDD[Tuple] sample: ("001","tom",18,60.0)
.map(t => Student(t._1, t._2, t._3, t._4)) // type: RDD[Student] sample: Student("001","tom",18,60.0)
.toDS() // type: Dataset[Student]
// register as a temp view/table
ds.createOrReplaceTempView("tableName")
|
分析以上代码,首先定义了一个Student类型,我们读取进来的数据要转换成此类型的一组实例。然后我们用Spark Core的map算子进行数据格式的转换,转换成了一批Student对象放在了RDD中,最后转换成Dataset[Student]类型。此时,Spark SQL的两个问题回答完毕:要操作的数据Student(字段名称和字段类型已知),要操作的数据从上游RDD直接可取。我们将这个Dataset[Student]类型的对象注册到Spark SQL系统供下面的代码使用
注1:Student类的定义不能放到方法体里
注2:要调用toDS方法,需要在调用前(一般在SparkSession的对象spark构造完毕后)导入一些隐式成员,即加上以下语句import spark.implicits._
- 构造Schema
Spark SQL使用Schema对数据的结构进行描述,Schema包含列名、数据类型、是否可空。我们可以直接构造出一个Schema告知Spark SQL我们的数据是什么结构。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
// construct schema
val schema = new StructType()
.add("id", DataTypes.LongType)
.add("name", DataTypes.StringType)
.add("age", DataTypes.IntegerType)
.add("score", DataTypes.DoubleType)
// read file
val rdd = sc.textFile("/path-to-file/") // type: RDD[String] sample: "001,tom,18,60.0"
.map(_.split(",")) // type: RDD[Array] sample: ["001","tom","18","60.0"]
.map(arr => (arr(0), arr(1), arr(2).toInt, arr(3).toDouble)) // type: RDD[Tuple] sample: ("001","tom",18,60.0)
.map(Row.fromSeq(_)) // type: RDD[Row]
val df = spark.createDataFrame(rdd, schema)
// register as a temp view/table
df.createOrReplaceTempView("tableName")
|
分析以上代码,我们首先构造了一个StuctType对象来描述数据结构,然后读取文件,与上面不同的是,最终转换成RDD[Row]类型,然后调用createDataFrame方法。createDataFrame方法的两个参数一个回答了数据来源的问题,另一个回答了数据结构的问题。
注1:文件加载部分可以进行简化
1
2
|
val df = spark.read.schema(schema).option("sep", "\t").csv("/path-to-bcp-file/")
df.createOrReplaceTempView("tableName")
|
使用了Spark SQL内置的一些工具进行简化。schema方法指定了要加载的数据的结构,csv方法指出了数据文件的格式,我们通过option方法指定一些选项(此处指定了分隔符以适配bcp文件)。加载选项的详细列表请参考ScalaDoc - DataFrameReader
注2:构造Schema部分可以进行简化
其实DataFrameReader已有类似API,即spark.schema("id LONG, name STRING, ...").option(...)...,其中schema方法接受Schema字符串并自动转换,但这个API是Spark 2.3.0新增,内部平台版本应该是2.1.x,还没有此API
鉴于此,我们可以实现一个SchemaInterpolator使之更易用,最终效果如下所示:
1
2
|
import SchemaInterpolator._
val schema = schema"id long, name string, age int, score double"
|
SchemaInterpolator的简易实现已附在本文档
注3:自描述数据源
有些数据源能描述自己的数据结构,例如jdbc json csv parquet等,这种情况我们也可以让Spark SQL自行推断数据结构,以csv文件为例
1
2
3
4
5
|
val df = spark.read
.option("header", true)
.option("inferSchema", true)
.csv("/path-to-bcp-file/")
df.createOrReplaceTempView("tableName")
|
Processing
准备阶段已经将临时视图注册到了Spark SQL系统中,我们可以直接提交要处理的SQL。此处仅给出一些样例,旨在揭示Spark SQL的各种可能,一般我们能想到的操作,都是可以做到的
spark.sql(sqlText)的执行结果是DataFrame(即Dataset[Row]),可以将结果保存、注册为新视图、替换之前的视图等
1
2
3
4
5
6
7
|
val df = ...
// create view
df.createOrReplaceTempView("t1")
val df1 = spark.sql("select * from t1 where t1.xxx is not null and ...")
// replace view
df1.createOrReplaceTempView("t1")
|
这段代码执行完毕之后,“t1"已经变成了筛选之后的数据,直接用就可以,因此,无需总是为给表取名字挠头
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import org.apache.spark.sql._
import org.apache.spark.sql.types._
import spark.implicits._
val schema = new StructType().add("k", DataTypes.StringType).add("v", DataTypes.StringType)
val rdd1 = sc.parallelize(Seq(("A", "aaa"), ("B", "bbb"), ("C", "ccc"))).map(Row.fromTuple(_))
val rdd2 = sc.parallelize(Seq(("B", "BBB"), ("C", "CCC"), ("D", "DDD"))).map(Row.fromTuple(_))
spark.createDataFrame(rdd1, schema).createOrReplaceTempView("t1")
spark.createDataFrame(rdd2, schema).createOrReplaceTempView("t2")
val df = spark.sql("select t1.k as k, t1.v as v1, t2.v as v2 from t1 join t2 on t1.k = t2.k")
|
更多JOIN操作请参考:LanguageManual Joins
Spark SQL提供了一批函数和运算符,我们可以直接在SQL里面使用,下面给出两个例子
例子1:过滤掉某字段的字符串长度小于10的数据
1
|
select * from t1 where length(t1.filed0) >= 10
|
例子2:根据出生日期,算出年龄
1
|
select *, int(date_format(now(), 'yyyy')) - int(year(t.birth)) as age from t
|
Spark SQL的内置函数列表请参考:Spark SQL, Built-in Functions
思考前面的例子2,根据出生日期计算年龄,用代码写我们有无数种实现方式,但是只用内置函数,好像很麻烦,所以我们实现个UDF,如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// define an normal function
val calcAge: String => Int = (birth: String) => {
import java.text.SimpleDateFormat
import java.util.Date
val now = new Date()
val fmt = new SimpleDateFormat("yyyy")
val thisYear = fmt.format(now).toInt
val birthYear = birth.substring(0, 4).toInt
thisYear - birthYear
}
// register udf
spark.udf.register("calcAge", calcAge)
// use it!
spark.sql("select *, calcAge(t.birth) as age from t")
|
分析以上代码,流程很清晰,写个普通函数 -> 注册到Spark SQL -> 直接在SQL中使用。
注意:尽量不要用这种方式!UDF对Spark SQL来说就是个黑盒,它无法对此做出优化,复杂UDF很有可能造成性能瓶颈。除非别无选择,否则不要用UDF
Spark SQL与Apache Hive的兼容性:Compatibility with Apache Hive
Hive语言手册(我们主要关注SQL部分):LanguageManual
SELECT:LanguageManual Select
Saving
数据保存的做法依然有很多,考虑到我们的实际需求,此处只推荐一种做法,如下所示
1
2
|
val df = spark.sql("select field1, field2, ... from t")
df.write.option("sep", "\t").csv("/path-to-result-dir/")
|
实际进行保存之前,建议执行一次筛选操作,用以确认要保存的字段并且保证字段的顺序,然后执行保存。
更多数据保存的相关选项,请参考ScalaDoc - DataFrameWriter
SchemaInterpolator
一个基于StringInterpolator的SchemaInterpolator实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
object SchemaInterpolator {
import scala.util.{Try, Failure, Success}
import org.apache.spark.sql.types._
implicit class SparkSQLSchema(val sc: StringContext) {
// InnerStructField -> index option, field
private type InnerStructField = (Option[Int], StructField)
// val schema = schema"a int, b string false, c double true some-comment"
// val schema = schema"0 a int, 2 c double true, 3 d string"
def schema(args: Any*): StructType = {
val str = sc.s(args: _*).trim
if (str.isEmpty) throw new IllegalArgumentException("Empty Schema String")
val innerSeq = str split "," map parseInnerStructField
innerSeq.head match {
case (None, _) => StructType(innerSeq.map(_._2))
case (Some(_), _) =>
val i2f = innerSeq.map({ case (oi, f) => (oi.get, f) }).toMap
val fSeq = (0 to i2f.keys.max).map(i => i2f.getOrElse(i, StructField(s"fake_name_$i", StringType)))
StructType(fSeq)
}
}
private def parseInnerStructField(str: String): InnerStructField = {
assert(str != null && !str.trim.isEmpty, "this is an empty string!")
val seq = str.trim.split("\\s+").toSeq
Try(seq.head.toInt) match {
case Success(index) => (Some(index), parseStructField(seq.tail))
case Failure(_) => (None, parseStructField(seq))
}
}
private def parseStructField(seq: Seq[String]): StructField = {
seq match {
case name +: typeStr +: Nil =>
StructField(name, typeStr)
case name +: typeStr +: nullable +: Nil if Try(nullable.toBoolean).isSuccess =>
StructField(name, typeStr, nullable.toBoolean)
case name +: typeStr +: nullable +: tail if Try(nullable.toBoolean).isSuccess =>
StructField(name, typeStr, nullable.toBoolean).withComment(tail.mkString(" "))
case name +: typeStr +: tail =>
StructField(name, typeStr).withComment(tail.mkString(" "))
case _ => throw new IllegalArgumentException(s"not a valid struct field: '${seq.mkString(" ")}'")
}
}
private implicit def typeStrToDataType(str: String): DataType = {
str match {
case "bool" | "boolean" | "Boolean" => DataTypes.BooleanType
case "byte" | "Byte" => DataTypes.ByteType
case "short" | "Short" => DataTypes.ShortType
case "int" | "integer" | "Integer" => DataTypes.IntegerType
case "long" | "Long" => DataTypes.LongType
case "float" | "Float" => DataTypes.FloatType
case "double" | "Double" => DataTypes.DoubleType
case "decimal" | "bigdecimal" | "BigDecimal" => DataTypes.createDecimalType()
case "string" | "String" => DataTypes.StringType
case "timestamp" | "TimeStamp" => DataTypes.TimestampType
case "calendarinterval" | "CalendarInterval" => DataTypes.CalendarIntervalType
case "date" | "Date" => DataTypes.DateType
case "null" | "Null" => DataTypes.NullType
case "byte[]" | "Byte[]" | "Array[Byte]" => DataTypes.BinaryType
case _ if str.endsWith("[]") => DataTypes.createArrayType(str.substring(0, str.length-2))
case _ if str.matches("^Array\\[\\S+\\]$") => DataTypes.createArrayType(str.substring(6, str.length-1))
// never hit this case, because type string was splited by ',' above
case _ if str.matches("^Map\\[\\S+,\\S+\\]$") || str.matches("^Map<\\S+,\\S+>$") =>
val i = str.indexOf(',')
val kt = str.substring(4, i)
val vt = str.substring(i+1, str.length-1)
DataTypes.createMapType(kt, vt)
case _ => throw new IllegalArgumentException(s"cannot resolve the type: '$str'!!!!")
}
}
}
}
|
开发一个Spark程序
参考环境准备中IDEA小节创建项目,然后将起始代码复制进去
注意构造SparkSession对象时master()方法接受的参数:如果是要在本地运行,使用"local[*]";如果是链接Spark Standalone集群调试,使用形如"spark://hostname:port"的Spark Master URL(可以在Spark Master Web UI找到);如果是要打成jar包放到公司的平台上跑,使用"yarn"参数
选用自己使用顺手的组件进行功能实现和测试,一般现在本地环境以样例数据测试核心逻辑。然后按照部署目标的要求进行打包,部署到实际环境中进行测试。应当注意运行效率方面,有时候还需要进一步优化。
开发常见问题
这里列出几个开发的时候比较常见的问题,此处列出的代码仅供演示,可能不完全正确
-
数据过滤不严谨
这种情况出现还算比较多,实际处理数据时应认真思考,尽可能筛掉异常数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
case class Student(id: String, name: String, age: Int)
val students = sc.textFile("/path/student-info.nb")
.map(_.split("\t"))
.map(a => (a(0), a(1), a(2))) // 可能出现数组越界异常
.map(t => Student(t._1, t._2, t._3.toInt)) // 可能出现转换失败异常
// 可以采用以下方式解决
val students = sc.textFile("/path/student-info.nb")
.map(_.split("\t"))
.filter(_.length == 3) // 保证数组长度,消除数组越界异常
.map(a => (a(0), a(1), a(2)))
.filter(t => Try(t._3.toInt).isSuccess) // 保证字段能正常转换
.map(t => Student(t._1, t._2, t._3.toInt))
|
以上演示了从数据格式上进行异常数据筛选,但某些数据从业务上也是不合法的,因此后续可能需要更多的filer和map进行数据筛选和变换
-
过多数据放到一个集合/节点
这种情况一般发生于使用Spark Shell进行快速数据分析时发生
1
2
3
4
5
6
7
|
rdd.collect().foreach(println) // collect算子把rdd中的全部数据放到一个数组了,很容易就会挂掉,这需要我们自行保证rdd中的数据不多
// 可以先统计下数量,如果发现不多,那么可以这么做
rdd.count()
// 也可以使用take
rdd.take(20).foreach(println)
|
-
使用外部变量
先看一个反例
1
2
3
4
5
6
7
|
val names = new java.util.HashSet[String]()
nameRdd.foreach(n => names.Add(n)) // 使用foreach进行结果整理
someRdd.map(x => {names.Add(x.name); x.other}) // map过程中“顺便”干点别的
// 或者这样
var sum = 0
intRdd.foreach(i => sum += i)
|
基于我们熟悉的面向对象编程,已经养成了这么一个习惯:遍历一个集合,在遍历过程中提取我们需要的信息放到之前定义的变量里。
在普通单线程Scala程序中,这么做虽然不推荐,但还是正确的;但是在Spark程序中,对RDD的操作如果这么干,是不正确的。要注意我们之前对RDD的并行化特点的介绍,Spark会把我们用λ表达的逻辑及其捕获的自由变量打包分发到每个节点,每个节点上的names sum与driver程序上的不再有任何关系,各节点的子任务运行完毕后,对变量的修改也不会反映到我们期望的变量身上,所以最终得到了错误的结果。
这类问题没什么统一的解决方案,只能是具体问题具体看,算是在强制我们熟悉一下函数式编程。
以上反例,可以这么改
1
2
3
4
5
|
val names = nameRdd.distinct.collect // 用distinct算子去重 当然也得保证name数量没有太多
// map中不要“顺便”做任何事情了,逻辑分离开单独处理就好
val sum = intRdd.reduce(_ + _) // 用reduce算子求和
|